Backstory #
I recently finished writing my master's thesis at Aalto University, which thankfully means I'm now able to graduate 🎉 (Let's not talk about how long it took, though). When I started work on my thesis, I decided to approach a topic that was surrounding me pretty heavily (as a British Citizen) at the time: Brexit.
I'm usually juggling three news sources that I read on a daily basis: The Guardian, The Financial Times, and The BBC. Intuitively, I could see leading up to the vote that across these outlets, some were very explicitly pushing an agenda (I'm looking at you, The Guardian). I wondered, is it possible to be able to determine the political bias of any of these outlets programmatically? It would at least be an interesting topic to look into, and perhaps I would get a nice clickbait title to use at the end of it that I could sell to various newspapers' competitors.
So, with the referendum vote behind me, I decided to see if I can find a way to split newspapers into pro-leave or pro-remain buckets, where articles could be fed into a model that would then spit out a EU philosophy alignment prediction.
I'll give you a half-spoiler ahead of time though: Things both did and didn't work at the same time. On the surface, I achieved my goal. But as is the case with most things, when you scratch beneath the surface, it's a little bit more tricky than that.
The Problem #
The British Media is Fundamentally Biased #
The British media are politically biased. I wish this was a particularly outlandish statement but sadly it isn't. Further still, I would even go as far to say that the British print media are unapologetically biased. See the following newspaper front pages for inspiration.
The British media often go as far as to state explicitly who or what they believe their readership should be voting for at each general election and certain referendums. The EU referendum vote in June 2016 was no different in this regard, with endorsements being given from most major newspapers: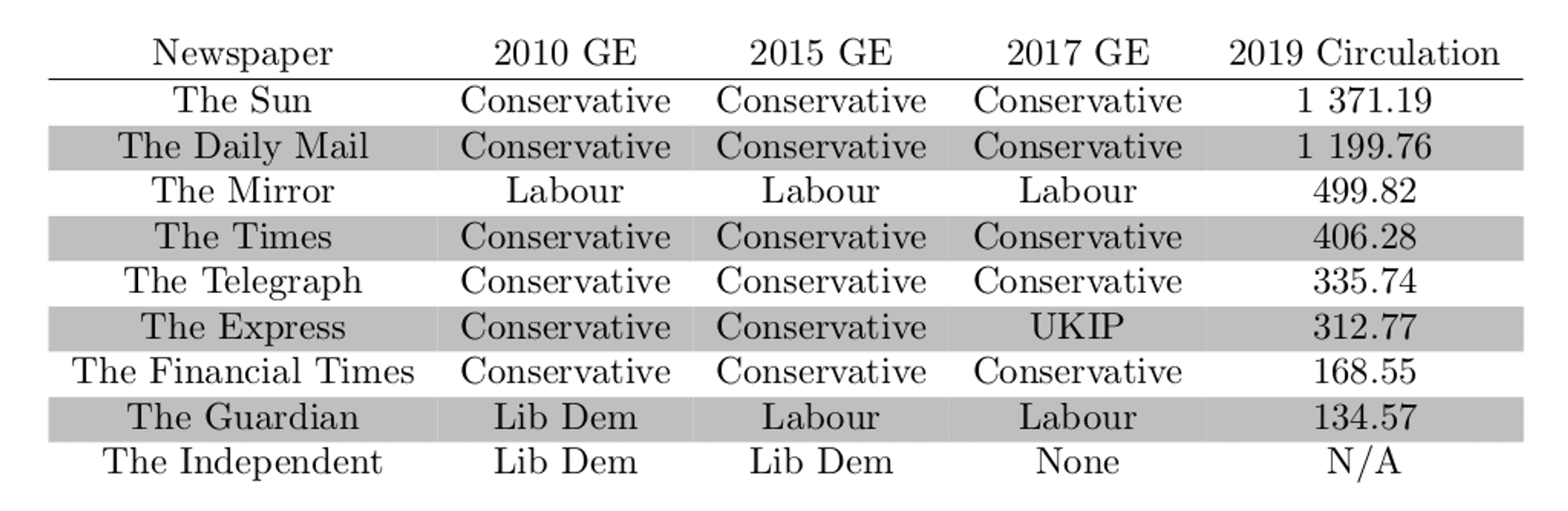
(By the way, I won't include citations here, but you can find them all in the full-length version of the thesis which can be downloaded here)
So hopefully now you have a small indication that the British print media have quite apparent political views. But, why might this be relevant to us anyway? Well, I'll explain why.
The British Referendum on its EU Membership Could've Gone Either Way #
I don't need to go too much into the details of the EU referendum itself, but the final result is important. A 51.89% : 48.11% split between pro-leave and pro-remain showcases how incredibly close the referendum was. If we consider the readership quantities shown in the endorsements table above (denoted in thousands), it be comes quite apparent that the conservative media (who for the most part, aligned with a pro-leave stance) have been able to reach a much larger portion of the British population than the liberal print media.
A study by Oxford University (citation [30] in the thesis) also backs this up: they performed a lengthy study on news articles published relating to the EU referendum, and manually labelled each article being either pro-leave, pro-remain, or neither. 41% were shown to be pro-leave, while only 27% were shown as pro-remain.
Studies in America (citation [41] in the thesis) have also shown that people are susceptible to believing that countries covered more regularly in the American media are more central to the "American interest". Countries that received negative attention from the American press, had the public interest follow suit and also employ negative opinions of such countries. It's a fair assumption to say that if the print media is capable of swaying public opinion in the US, it's certainly very likely to happen in the UK.
Perhaps if the referendum was a blowout in one direction, then public perception regarding information presented to them as facts may play less of a role here. But, in such a close vote that is so critical to British industry, culture and international relations, it's hard to not consider this more deeply.
So with this in mind, I sought to find a way to deterministically identify Brexit-relating political opinions in the print media. Next, I'll tell you about how I tackled this problem.
The Solution #
Gated Recurrent Neural Networks To the Rescue! #
I'm not going to go deep into the technical background here. If you'd like to find out more about exactly what a recurrent neural network is, please refer to the thesis. I go into (quite frankly) excruciating detail on the exact technicalities of recurrent neural networks (RNNs).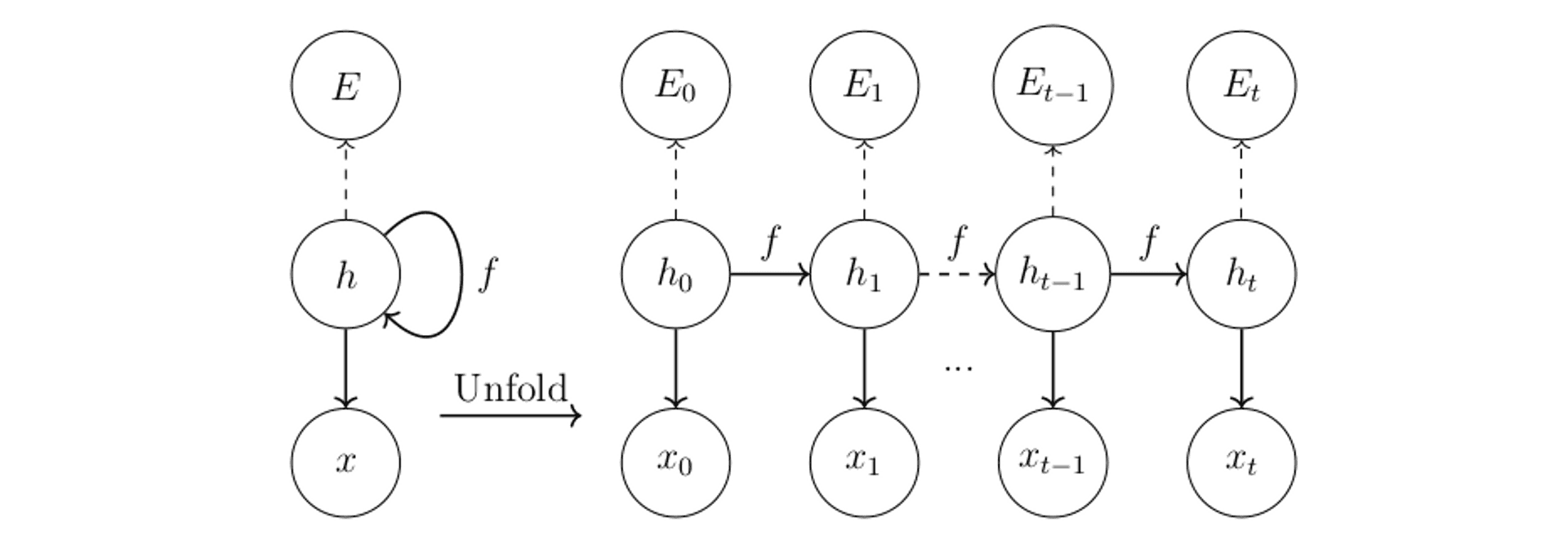
In one sentence, an RNN (shown above) is a type of artificial neural network that uses a hidden state (shown above as h) and an objective function f that is reapplied over sequential data in order to generate an output prediction. For example, if we have a sentence such as "Boris Johnson backed leave for his own gain", each word in that sentence is fed into the network at each hidden state time step, and ultimately we are left with a hidden state that is a product of all the words in the sentence, fed through the network. This approach allows us to process sentences of varying lengths, without the need to squish them all into the same length beforehand.
But, one drawback of these kinds of networks is they can get very confused when sentences (our input data) gets long. You can read about it more in the thesis but the problem is called vanishing / exploding gradients. Using gated RNNs allow us to manage these long sentences a bit more effectively.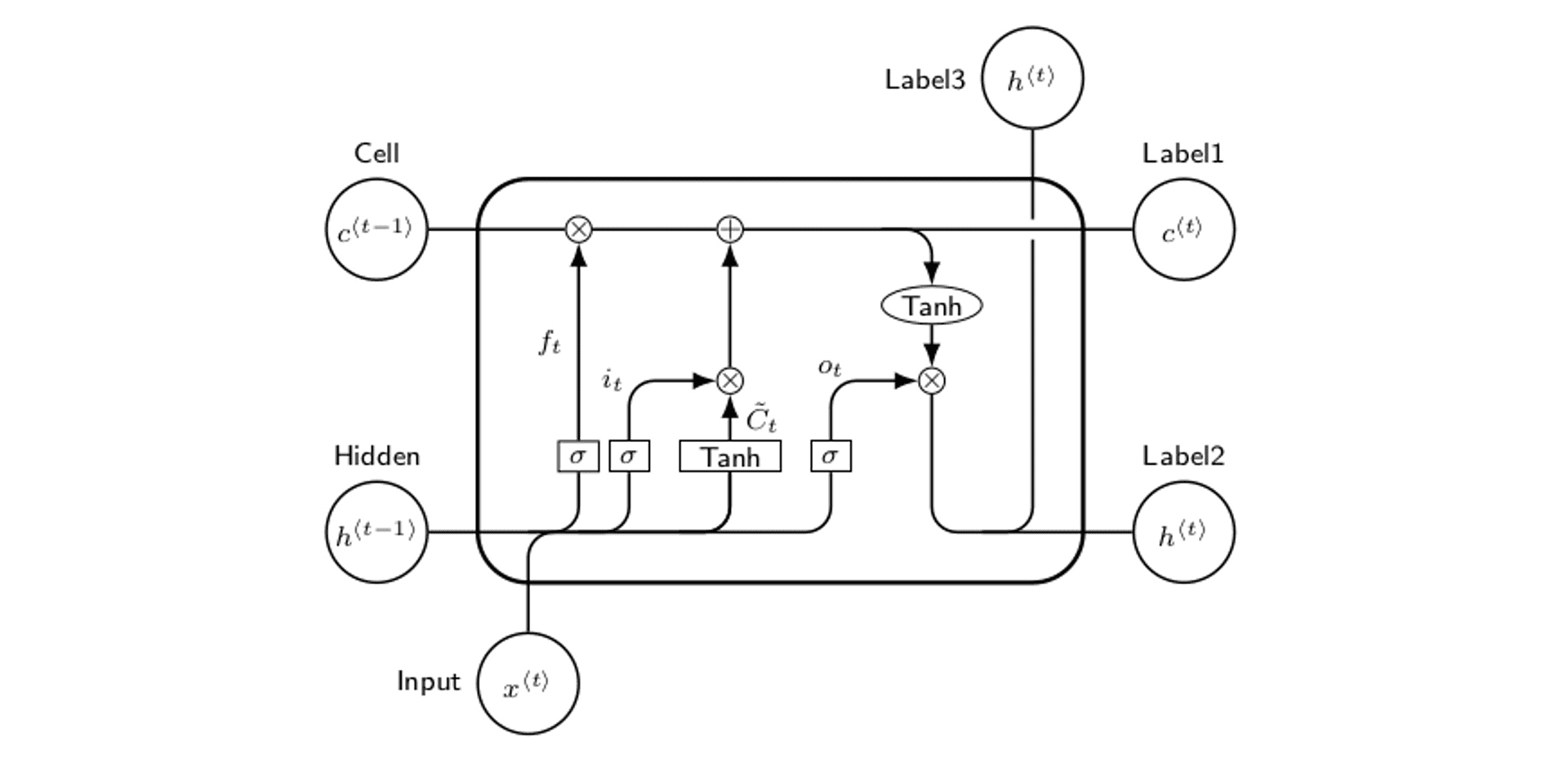
Here's an example of a kind of gated RNN, called a long short-term memory cell. There's no exam or quiz associated with this blog post so I won't quiz you on it, but they're pretty cool (Maybe I'll go into the maths behind these in another blog post at some point). All you need to know is that this and another type of RNN called a Gated Recurrent Unit (GRU) were the main two types of RNN that I used in this study, as they're best known to be able to manage longer sequences of input data.
OK... How About Naive Bayes? #
One of the most simple approaches to sentence classification is the Naive Bayes. If we have a sentence X, and a prediction y, we can write the Bayes theorem as follows: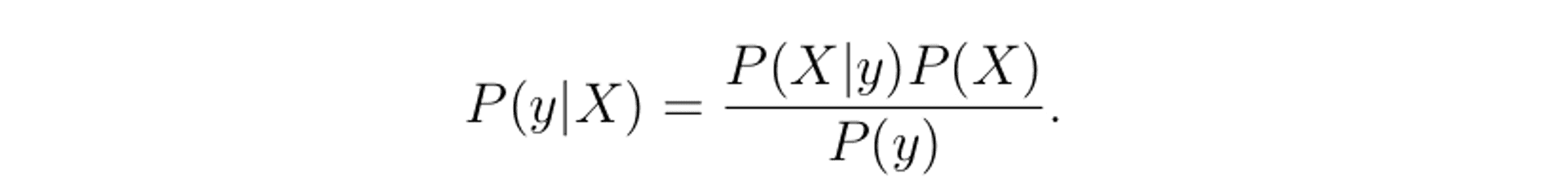
All we're saying here is the probability of a label y existing, given a sentence X. We can then calculate this using some existing probabilities that we're able to compute intuitively. One underlying assumption with Naive Bayes is that each feature is independent of each other. In this context we cannot say that each word is independent of each other in our sentence; each word influences the surrounding context words. With this in mind, I made the assumption that while Naive Bayes would serve as an interesting base, it probably won't provide results to contend with the far more sophisciated RNN-based approaches.
....ohhhh boy.
Experimentation & Results #
So, practically speaking, I pulled 101415 sentences from 9 different news outlets, and assigned each of them a bias value based on the explicit endorsements provided by that given newspaper. For this study, I used the label 0 to indicated pro-remain, and the label 1 to indicate entirely pro-leave.
Then, I trained a range of RNNs in a variety of different configurations (i.e I tweaked various paramters for each model that was trained). Once I felt that I had trained enough different configurations, I picked the 4 best performing models, and compared these against the more simple Naive Bayes approach.
One thing that's worth mentioning here is that RNNs would take roughly something in the realm of 15 minutes to train, on my Linux workstation with a powerful dedicated GPU. The Naive Bayes would take something around 10 seconds to train.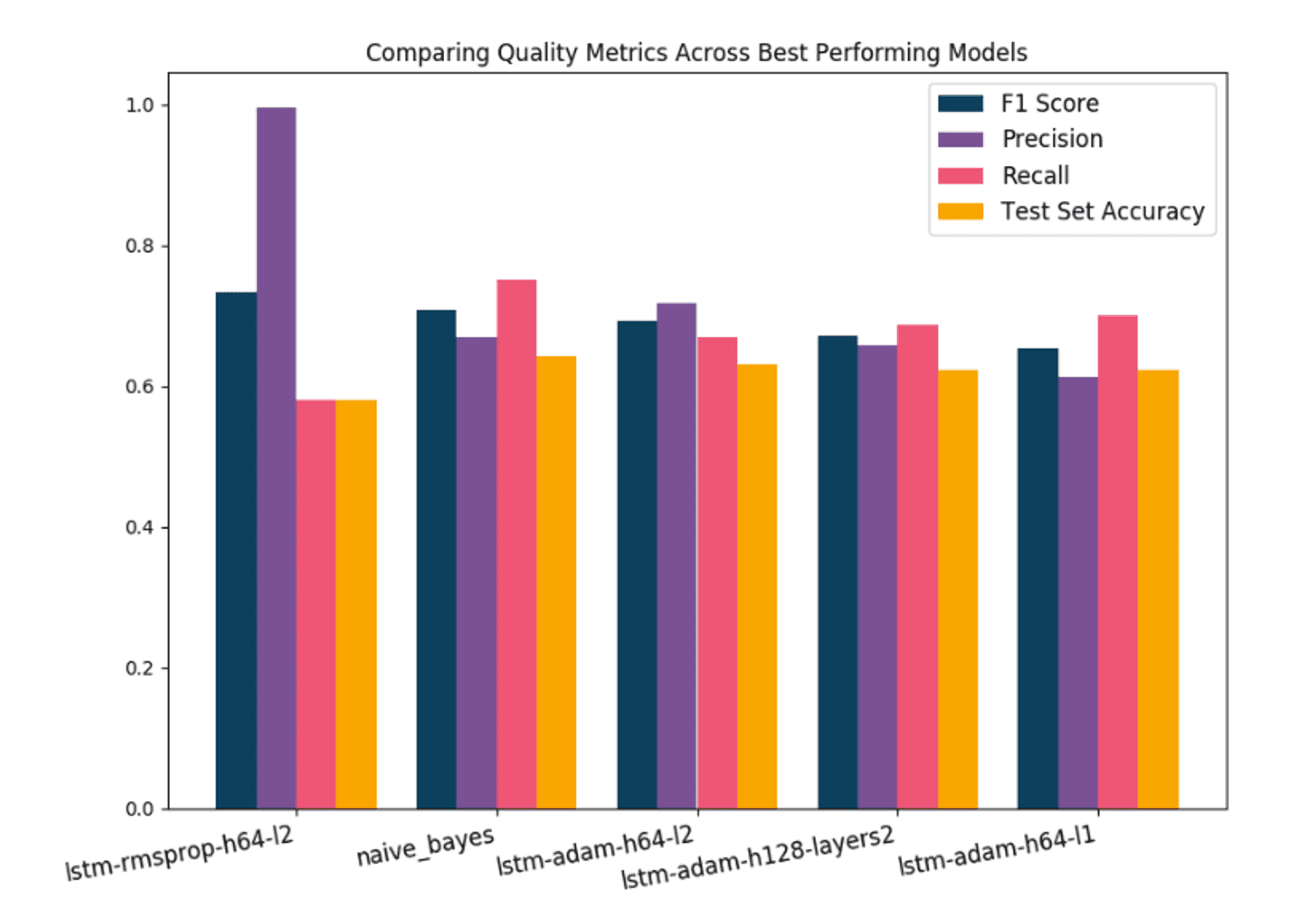
In the above diagram I'm showing the 4 best performing models (all of which are LSTMs, a type of RNN) with a range of different hyperparameter configurations, compared the Naive Bayes approach. The most important metric to look at in this diagram is the F1 score, which I used as the primary method of gauging a models accuracy. Think of the F1 score as a kind of improvement over a standard accuracy percentage, that takes into account enriched data such as the number of correct positive predictions (i.e correctly predicting pro-leave biases in pro-leave labelled sentences), among other things. Again, if you want to find out about exactly what makes up the F1 score, you can find it in the thesis.
For reasons I won't go into here, the leftmost model, lstm-rmsprop-h64-l2 didn't actually learn anything meaningful in the data, it just happened purely by chance that it was able to give quite good predictions over the data that I fed into the network. It's possible to tell this by the large difference between precision and recall values for that model.
So, if we discount that model, the next best performing model (by F1 score) is... yep, the Naive Bayes. Whilst this was pretty disheartening, I can also see in this graph that the 3 next best performing models weren't far off in terms of F1 score.
Next, I wanted to see what kind of predictions my best models gave over real-world data. So I fed in a few newspapers that had the most opinionated stances surrounding Brexit, to see what kind of predictions my model gave: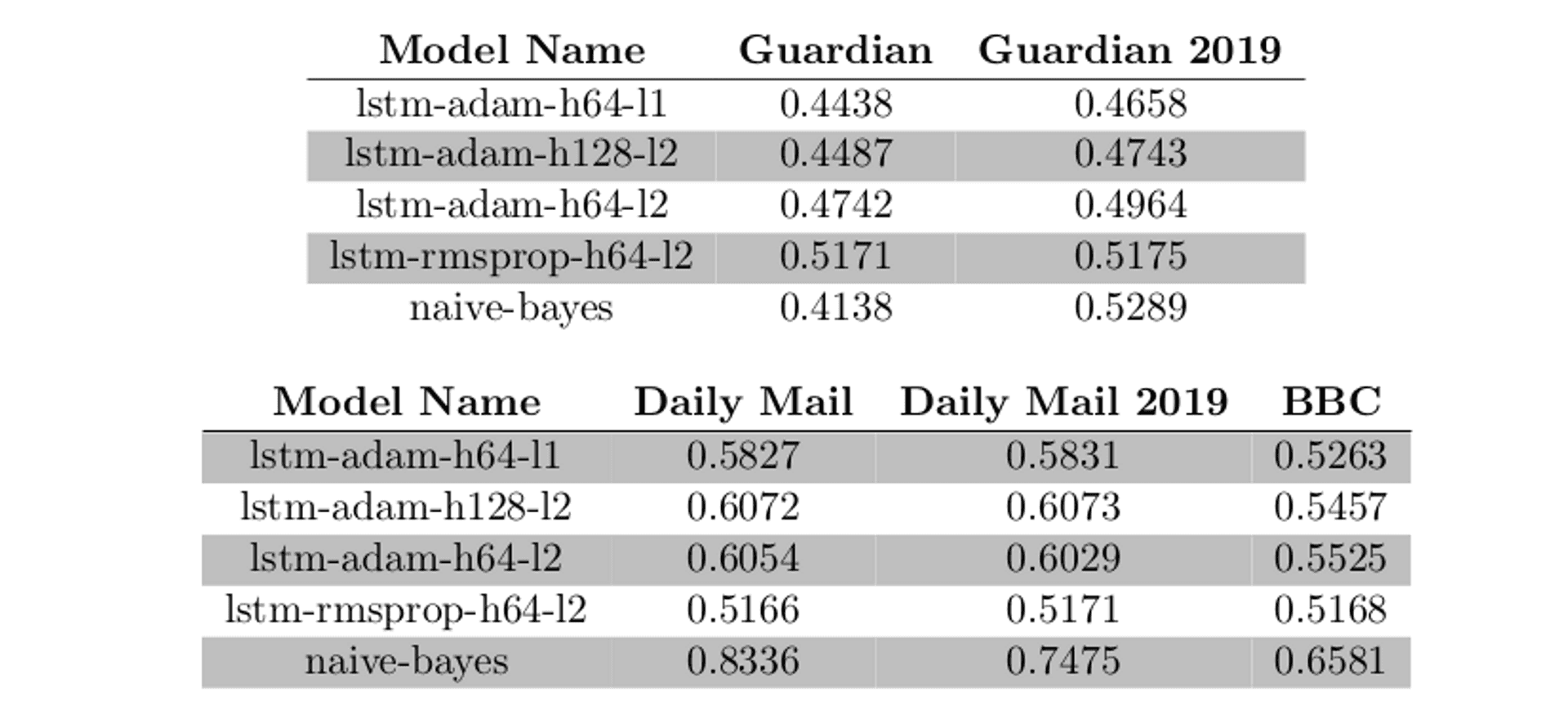
There's a few interesting things to note here. Firstly, we can see that all of the models correctly identified The Guardian as pro-remain, even over more recent 2019 data. The inverse holds for The Daily Mail, where all models found it to have a pro-leave bias.
Next, we can see that all of the models give a pro-leave prediction to the BBC, a supposedly unbiased outlet. The most simple model, the Naive Bayes, even goes as far as to give it a 0.65 predition, which is quite a confident prediction that the articles that the BBC generated in the lead up to the EU referendum vote had more resemblence to other pro-leave articles, rather than pro-remain ones. Does this mean that we can say that the BBC was publishing material that swayed their readership towards a pro-leave vote? I'll leave that up to you.
Finally, we can see that the Naive Bayes model gave the most confident predictions out of all of the best models. In this case, it rather cements the fact that the most simple approach, in this context, was the most effective one.
Learnings #
Using Newsaper Endorsements as a Ground Truth Doesn't Work #
Here we applied ground truths very very aggressively. We make the assumption that in all EU referendum articles published by certain outlets leading up to the referendum vote, these have a certain labelling that is either 0, or 1. There is no inbetween. Intuitively we know this isn't the case. Journalists have varying opinions within newspapers, and of course its possible that journalists publish content that is not aligned with the endorsements provided by the newspapers. There's more that could've been done here but that would've turned this study into a 4 year one, not a 2 year one.
Correlation Does Not Mean Causation #
Fundamentally, we're able to produce some nice clickbait headlines with this work. We could say that this study shows that the BBC posessed a pro-leave alignment in its published articles in the year leading up to the EU referendum. However, we can't really say this. We can only really say that the BBC published articles that bear more of a resemblence to pro-leave articles, than pro-remain ones.
Neural Networks are Data Hungry #
As mentioned before, I used 101415 sentences (each labelled as either pro-leave or pro-remain) to train my neural networks on what intuitively constitutes a certified biased article. However, my results show that this still isn't enough. Our of my neural networks that performed the best, all of them were using incredibly simple configurations. Anything more complex lead the RNN to believe that there were complex relationships in the data that simply weren't there (this is called overfitting). I needed far more data to make my RNN based approaches more viable.
Keep It Simple, Stupid #
Finally, this is the ultimate lesson in the KISS principle. I wanted to look into using "cool" technologies to be able to solve this problem. I did that, and it was fun learning about these things in the process, but I definitely should've considered the most simple approaches out of the gate. Had I done that, I probably would've taken a slightly different approach in my study - building up from simple models to progressively more and more complex ones, until I found a model that performed the best.
To Summarise #
I wanted to be able to create a pro-leave or pro-remain political bias predictor using a type of artificial recurrent neural network called a recurrent neural network. I really enjoyed working with them, and I got some results that indicated that certain newspapers do possess political leanings that can be detected at a sentence level. That's pretty cool to me.
As is the case with these things, there's so much more that can be done. natural language processing is an entirely different world now compared to the one when I started work on this thesis, and there's now more cutting edge technologies that should be able to pick up the pitfalls that I encountered here. Problem is, it's going to take more recent data, more time and more funding. But, it would most likely be an incredibly insightful study that hasn't really been done before.
So... time to go for a Ph.D.? Give me some time to think about that and I'll get back to you.
Quick Links #
As mentioned in the article, you can find the full master's thesis document here.
I also gave a presentation about the thesis. It's probably the most short-form way to find out about the results of my study. You can find it here.
Published